
The development of AI is a fascinating topic and one that I explored in more detail whilst co-writing my latest book: AI as a Service, available through Manning Publications here: https://www.manning.com/books/ai-as-a-service. In the first post in this series, we looked at the very early development of AI.
In this second of a series of four blog posts, we look at the development of AI from the first AI winter circa 1970 to the second which occurred in the early 1990s. The term AI winter refers to the cold winds of a lack of interest or belief in the subject and, more significantly, a lack of funding.
As we saw in the first post, the early promise in the field of AI failed to live up to the hype. This over promise / under deliver pattern was sadly to be repeated again in the 1980s.
Much good work had been done in the field, indeed a lot of the conceptual underpinnings of modern AI had been developed. Key among these was the notion of a neural network of perceptrons.
However, other AI based techniques which had been identified during the 1960s were about to come to the fore and the 1980’s saw renewed interest in AI with the development of so called expert systems.
Expert Systems
Expert system use logical rules and decision trees combined with a knowledge base derived from human experts in a specific field. Typically use cases included medical diagnosis or spectral analysis.
The basic premise of an expert system is that rather than encoding logic in an imperative programming language, the programmer should work with a domain expert to develop a knowledge base of facts and rules. An inference engine is then used to solve for a given set of inputs. Whilst this seems fine at a conceptual level, pragmatically these systems proved to be brittle and of limited utility.
An example of an expert system language is Prolog which was first created in 1972. To get an idea how this might work take a look at the example below. This code defines some facts, in this case the land borders between European countries and a rule to find neighbouring countries.

For example to find the neighboring countries of Holland, one would run.

If this seems a bit familiar, it’s because we still use this type of approach in some systems today. Usually in embedded rules engines such as Drools.
Expert systems found a niche during the 1980’s, but in the background work was progressing on the further development of neural networks. Let’s take a moment to review the key concepts underpinning a neural network as this will help to contextualize the forces that later came together to create the current modern wave of AI and Machine Learning.
The Perceptron
In the last post we mentioned the perceptron without actually defining what it is. It is important to understand this concept as it underpins a lot of our modern AI tools. The good news is that it’s actually surprisingly simple!
The perceptron was first conceived in a 1943 paper entitled ‘A Logical Calculus of Ideas Immanent in Nervous Activity’ by Warren McCulloch and Walter Pitts. The original McCulloch-Pitts perceptron was somewhat simpler than that described here, allowing only binary inputs and using a step activation function.
The modern perceptron was first developed by Frank Rosenblatt in his 1962 book, ‘Principles of Neurodynamics’.
To understand how a perceptron works, let’s firstly look at a human brain cell or neuron. This is depicted in Figure 1. You have many billions of these in your brain!
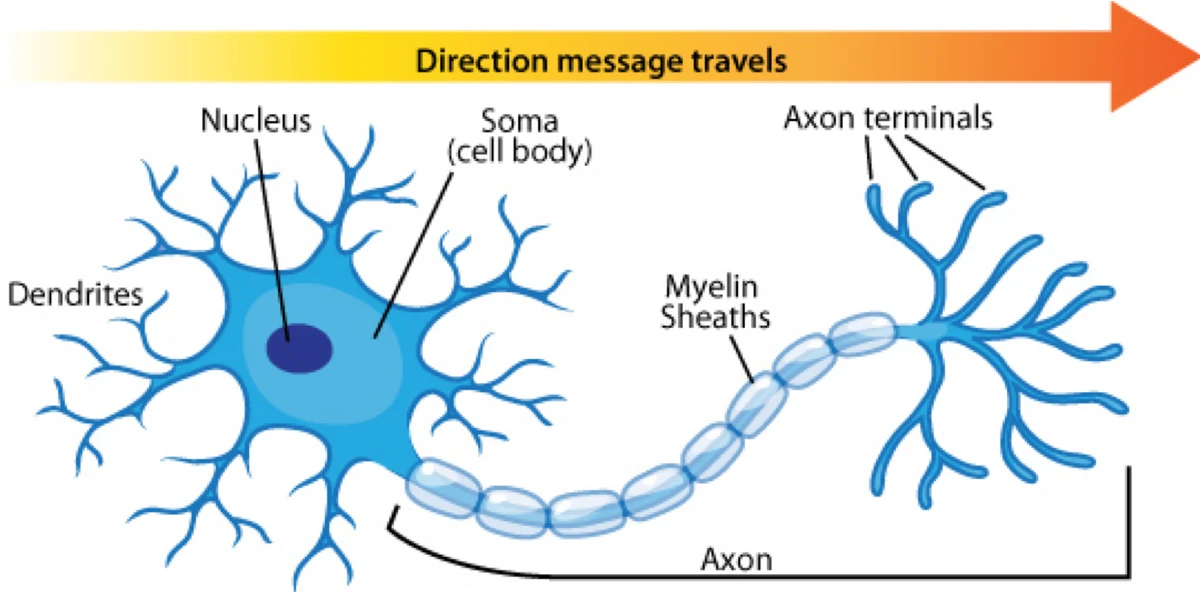
Figure 1 Neuron Structure
The two key structures in a neuron are dendrites and the axon:
- Dendrites form the input channels into the neuron. Neurons connect into downstream neurons through dendrites.
- The axon is the output channel of a neuron. The axon connects to the dendrites of other neurons.
- The contact point between an axon and a dendrite is called a synapse.
Whilst a single neuron is actually a very simple entity, it is the multi-layered inter connectivity of many billions of brain cells from which intelligence and consciousness arise. A perceptron is essentially an attempt to mirror the operation of a neuron in a machine. Figure 2 depicts a perceptron.
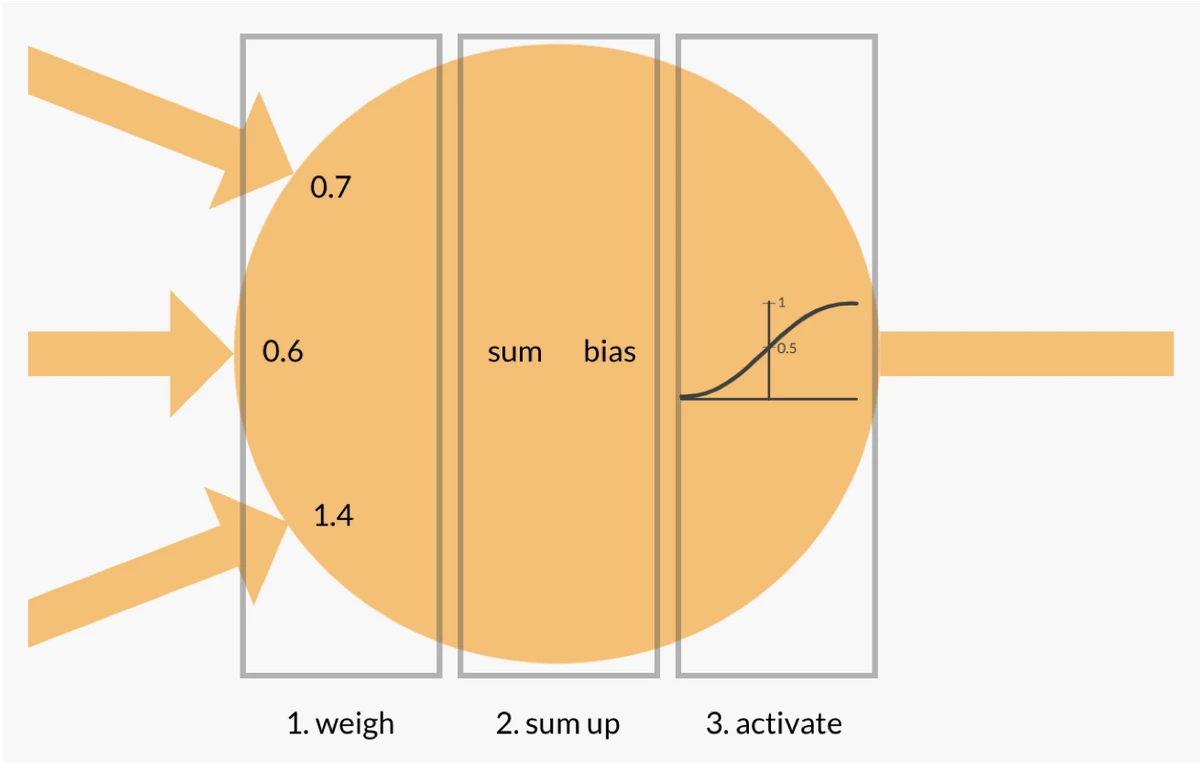
Figure 2 Perceptron
In a similar manner to a neuron a perceptron has multiple input channels (dendrites) and a single output channel (axon). As inputs are passed into the perceptron a decision is made as whether the output signal should be fired or not and what the output level should be. This is computed through a simple process.
- Multiply each input signal by a ‘weight’ value
- Sum up the total of weighted signals
- Add a bias value
- Pass the sum value through an ‘activation function’
- Output the resultant value
That’s it! At the core a perceptron really is just some very simple maths. So how do we achieve results with this simple processing. As with our brains, it is the result of combining many perceptrons into a network that produces the emergent complex results.
Neural Network
Figure 3, depicts a simple multi later network. Each node in one layer of the network is connected to each node in the next layer.
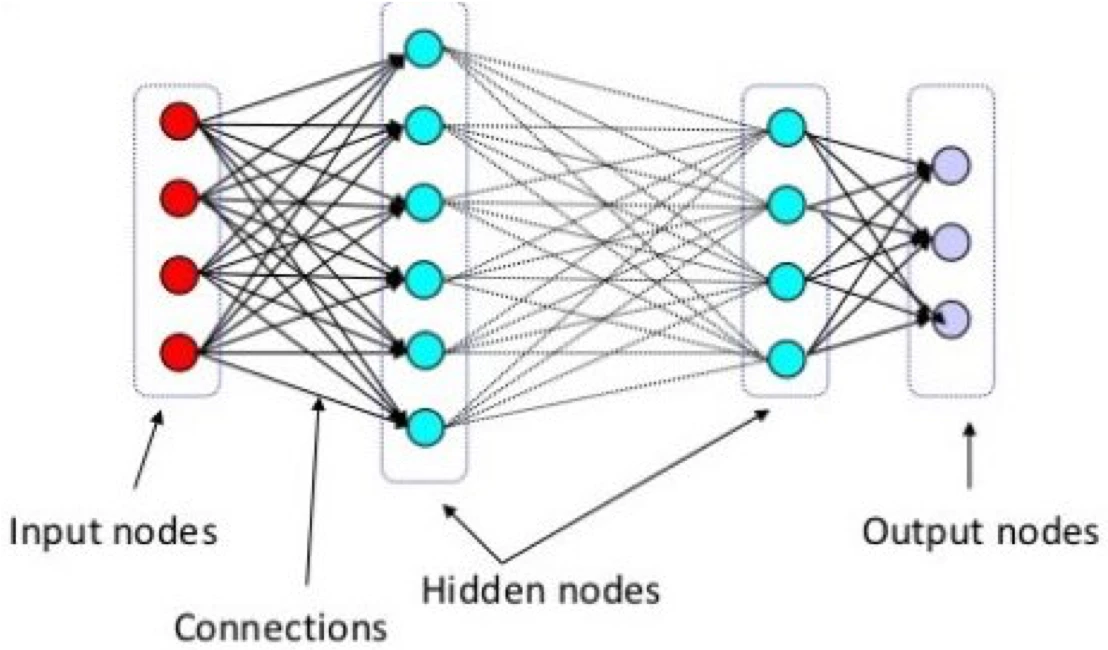
Figure 3 Neural Network
Each node in the network is of course just a perceptron. You may have heard that a neural network needs to be ‘trained’ in order to ‘learn’ how to do a specific job. What does this entail exactly? Simply this:
Training a neural network is the process of adjusting the weights and bias values for each node in the network.
That’s it! So, if it’s that simple, why do we need so much compute power for neural networks to be effective? The problem is really one of scale.
- In order to be useful a network needs a significant number of nodes or perceptrons
- The nodes are layered and there are many connections between them
- A network must be fed a large volume of training data to effectively adjust all of the weights and biases across the network for it to reach some degree of accuracy
In other words, in order to train a network, a lot of numerical computation must be done and this just takes time. The more computer power you have the faster these computations can run and the faster the network can be trained.
The Second AI Winter
Towards the end of the 1980s it became clear that the early promise of expert systems was not going to be realized. This fact, coupled with the rise of commodity PC hardware meant that companies would no longer invest in the expensive custom hardware required for these systems.
Whilst researchers had made strides in advancing the field of neural network development, both in network architecture and improved training algorithms such as back propagation, still the available compute power was insufficient. Interest again waned in the subject and the second AI winter began.
References
- Prolog listing: https://www.tjhsst.edu/~rlatimer/assignments2004/mapcolorsProlog.html
- Figure 1: image sourced from: https://en.wikipedia.org/wiki/Neuron
- Figure 2: image sourced from: https://en.wikipedia.org/wiki/Perceptron
- Figure 3: image sourced from: https://en.wikipedia.org/wiki/Artificial_neural_network


")