

DevOpsDays came back to New York City this January 2018 and was a huge success. This day brought together 300 development, infrastructure, operations, information security, management and leadership professionals from all around the world to discuss the culture and tools to make better organisational decisions and innovative products. The event’s schedule consisted of a mixture of single-track presentations, Ignite talks and the open space format for which DevOpsDays is known.
The main aim of our visit was to connect and network with like-minded individuals who see the many benefits of using DevOps to increase their software deployment velocity, improve software quality, and automate as much as possible.
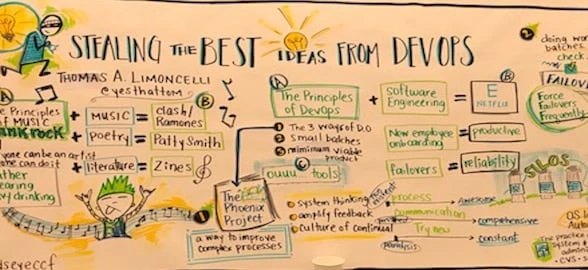
DevOps, Almost 10 Years, What A Strange Long Trip It’s Been
John Willis is Vice President of DevOps and Digital Practices at SJ Technologies and was the first speaker of the day. He reflected on how far DevOps has come over the past 10 years from the early Cfengine saturation based on principles of convergence and desired state, to Continuous Delivery becoming mainstream around 2010.
Containers and immutable delivery models 2015-2016, and everything else in-between up to and including Dr. Cook, Dr. Woods and John Allspaw’s recent 2017 Stella Report. He finished up with a look at where we are today and a quick glimpse at some potentially interesting new influencers (Cynefin and Simon Wardley’s Mapping).
DevOps is more about customer feedback and quick learning than culture, process, and tools
The next speaker was Kishore Jalleda the former Head of Production Engineering in Yahoo’s Publisher Products unit. He spoke about people’s misconception when it comes to “being” DevOps, stating that although not wrong just being a team of “developers doing operations” doesn’t make you truly DevOps.
Lots of teams think they are doing DevOps, but not seeing the entire picture. Kishore outlined that even though you’ve gone through this huge transformation, what now?
Your customers don’t care that you are a DevOps shop/factory, what they do care about however is how your product adds value to their lives. So you must be conscious of the impact the DevOps transformation has on your customers, draw feedback from this, learn more about your customers and inevitably better your DevOps capabilities as a result.
Kishore spoke about Ops engineering and its value to every DevOps team! Ops engineering is a branch of engineering that is mainly concerned with the analysis and optimisation of operational problems using scientific and mathematical methods.
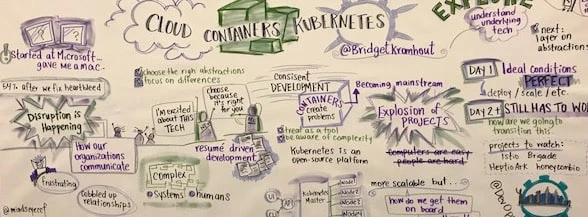
Cloud, Containers, Kubernetes
The day continued with Bridget Kromhout who is the Principal Cloud Developer Advocate at Microsoft. Bridget often organises DevOpsDays herself at Microsoft, highlighting the fact that MS are one of the biggest contributors to OSS on Github. Bridget was issued an Apple MAC by Microsoft to promote Linux on Azure, which may surprise some readers who still think that Microsoft are still only Windows focused. Bridget spoke about Conway’s law and its usefulness in developing your organisational structures and info systems design.
“Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.” – Conway’s Law
The interface structure of a software system necessarily will show a congruence with the social structure of the organisation that produced it. Because the design that occurs first is almost never the best possible, the prevailing system concept may need to change. Therefore, flexibility of organisation is important to having an efficient design.
She spoke about how cloud computing helps you to emphasise outcomes over technology, choosing the right abstractions, and focusing on what helps you differentiate your product/service. Using these insights to better your processes as a result. By way of example, she focused on the evolution of containers:
- Cloud Foundry 2011
- Docker 2013
- RKT 2014
- Kubernetes 2014
You should always be aware of the complexities of technology, remembering to use it as a tool not the goal. Kubernetes does not inherently make apps easier to use, as micro-services have their own issues, and troubleshooting is often like trying to solve a murder mystery!
Microsoft’s Azure cloud offerings include AKS, GKE, EKS:
- AKS (Azure Container Service) – delivers the popular container orchestration technology with a simplified user interface and hosted control plane. Clusters are self-healing and the software automatically upgrades. AKS builds on-top of Azure’s existing ACS (also Azure Container Service) without charging for the new management functionality.
- GKE (Google Kubernetes Engine) – is a management and orchestration system for Docker container and container clusters that run within Google’s public cloud services. Google Kubernetes Engine is based on Kubernetes, Google’s open source container management system.
- EKS (Amazon Elastic Container Service for Kubernetes) – is a managed Kubernetes service within AWS. It uses Kubernetes upstream, and is replicated across three masters in different Availability Zones. It uses IAM for role-based access control, PrivateLink to reach the masters from your own private network and VPC.
Bridget concluded with some wise words: organisations should celebrate being the settlers rather than the pioneers, and celebrate scaling up their operations. Celebrate means not being woken up at 3 am. Silos are for grain not orgs, and always remember that the Cloud is just someone else’s computer.
Accelerate DevOps Adoption With A Dojo
Another useful session was by Manish Patel . (Dojo Coach at Verizon, NJ)
He spoke about Verizon’s immersive learning program called “dojo”, which means the place of learning. They have three in the US and two more internationally. The idea is to accelerate learning by combining agile principles and designing as a team. Engineers get better at understanding the customer and the products they’re building.
Manish’s coaching philosophy is:
- Chartering – four hour initial meeting with teams
- Sticky learning – which consists of knowledge + failure + context + constraints + perspective and repetition.
- The use of shared understanding – David Kelly said by using this method “You get to a place you just can’t get to in one mind”
- Dudes Law – Value equals Why divided by How ( V = W / H, where V is value, W is why (intent) and H is how (mechanics).
- Each effort in the Dojo lasts 6 weeks.
- They do not use Jira, instead preferring Post-It notes on a whiteboard.
- Some teams have adopted the techniques well, whereas others are more resistant. What is important to remember is that working together works! Communication barriers must be overcome, and understanding the “why” is key to succeeding.
Moving fast at scale
Randy Shoup, a 25-year veteran of Silicon Valley, delivered an interesting session discussing the organization, the processes, and the culture that can help a company move fast and even accelerate faster as it grows. Most companies slow down as they get larger, but some actually speed up. Randy used his experience leading high performing engineering teams at Google, eBay and Stitch Fix to explain how a company can better itself over time instead of slowly unravelling under its own weight. Teams are cross-functional in an organization, meaning that each team has all the skill sets it requires to do its job, while at the same time relying on other teams for supporting services, tools, and libraries. Process-wise, it means doubling down on practices like test-driven development and continuous delivery. But why choose between speed and stability? The DevOps handbook says that high performing orgs deploy quicker, recover from failure quicker, with a lower failure rate. The high performing orgs have speed AND stability – the things that let us go fast also make us stable.
Some aspects of moving fast:-
- Few things more done– It is important to deliver full value earlier rather than later. The time value of money is something to keep in mind (more benefits in having something now than in the future) Incremental delivery can be used to allow for small value rather than everything at the end. “When you solve problem one, problem two gets a promotion”
- Conway’s law says you ship your org structure. Small independent teams lead to flexible internal infrastructure. Larger teams = larger systems. As a team grows, they should split into two and project work should fall between these teams.
- Prioritisation – Scarce resources call for prioritisation and trade-offs and it’s important when working with limited resources to use them correctly and to their full potential to achieve the overall goal. The best case scenario is having this driven by ROI (return on investment).
- Quality discipline– Quality and reliability are priority 0 features. If the site isn’t up it doesn’t matter how good it looks because no one will be able to see it. Developers should be responsible for features, quality, performance and reliability. Use test driven development. It gives you room to make mistakes and inevitably gives you better code as a result. You feel more at ease breaking things and gain confidence, tests are executable documentation for how the code is supposed to work.
And that was the first DevOpsDay attended by fourTheorem! Although we didn’t get to attend the open space sessions, overall it was an extremely successful and informative day and we will definitely be marking our diaries for this enlightening event next year!
If you are interested in how fourTheorem can help you with Machine Learning on AWS, DevOps, cloud migration and architecture, please contact us and we’ll be happy to help.