

I was recently given the opportunity to speak at microXchg in Berlin, a fantastic community-run conference on microservices and serverless architectures. My talk was about moving away from Functions-as-a-Service (FaaS) as the focus of Serverless. The more I do with Serverless, the more I feel that Serverless is about embracing all of the managed cloud-native services and, ultimately, writing as little code as possible. Thinking about FaaS alone is a narrow view that misses out on the real benefit of Serverless. Every architecture decision is an opportunity to implement fewer Lambda functions and adopt a faster, easier, cheaper and less maintenance-heavy alternative.
Why would you want to avoid Lambdas? If the hype is to be believed, Lambdas are the whole reason behind the rise of serverless and the solution to all your compute needs! Of course, it’s not that simple. Sure, Lambdas let you deploy your code quickly and take away many orchestration and scaling headaches when compared to many instance or container-based deployments. They still have their drawbacks. Let me quickly summarise some of the constraints of Lambda today.
The Limits of Lambda
The limits of function deployment size (250MB total unzipped including all layers) can get in the way. I have seen this happen with some simple Python functions that included some large library dependencies. Time spent trimming package dependencies down is time not spent building value.
Lambda functions give you no real persistent filesystem access. Any data you need, you have to fetch, or it has to come from the triggering event itself. This adds latency to your function execution. You pay for ‘compute’ while your function is simply waiting for I/O.
Much of the time, a Lambda function is far more than you need. If all you want to do is some simple data transformation, or proxy an event from one source to another target, you don’t necessarily need all the overhead of a container runtime. A lightweight execution environment without the cold start and full OS+runtime would be a great addition. I can definitely see AWS and other providers adding no-code services for bridging event sources. (Update: Amazon EventBridge, the new, major iteration on CloudWatch Events, looks like it’s heading this way)
Local development and deployment for developers is still a big issue. Looking back at Docker, we had an environment that gave us a development environment that matched production closer than ever before. With Lambda, the local execution options are limited by comparison. As soon as you move beyond the canonical API Gateway + Node.js Lambda examples, achieving a powerful, effective development environment becomes too difficult. The time for developers to get code changes running should be close to zero. Otherwise, you can lose focus and suffer a major context switching overhead as you try to occupy the deployment time with other tasks.
Debugging functions remotely is difficult. A Lambda container is not directly addressable, so you can’t just connect on a remote debug port or get shell access without a lot of effort. There are some workarounds available but nothing that is really developer-friendly. You can certainly argue that remote debugging should not be necessary and that there are other ways of troubleshooting, like having an effective local development environment where you can closely replicate production conditions. See the previous point, however.
Does all of this mean that Lambdas are over hyped nonsense to be avoided?! Absolutely not. It’s just better to adopt these things with your eyes open. Too often when we adopt new technologies, our enthusiasm blinds us to the obvious drawbacks and pitfalls. By understanding and admitting these drawbacks, we can actually make better use of the technology in the right way and avoid applying it when it’s really not the best fit.
So what do we do when Lambda is not quite the right fit? Well, first avoid writing any code. Then, ask whether you need FaaS at all or if you can use any of the many other cloud compute services.
Use Managed Services
The majority of code you write should concern unique business logic. Where possible, avoid writing code for any part of your system that is mundane and implemented in many other software systems, frequently called Undifferentiated Heavy Lifting. Use cloud managed services. While you can use libraries, frameworks and components, these can have their own maintenance burden and you still have to maintain the infrastructure they run on. Integrating with cloud managed services relieves you of this significant burden.
Such services can be found outside the realm of your chosen cloud provider. Even if Amazon Web Services has no off-the-shelf service for your specific needs, look beyond AWS and evaluate third party offerings. For example, if you want to implement a search feature in your application, you might evaluate a fully-managed Elasticsearch service such as Elastic or a managed search and discovery API like Algolia.
Use Step Functions
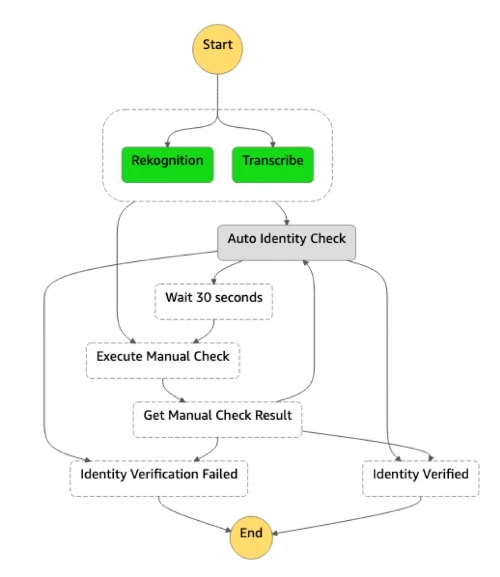
When you’re looking to orchestrate a combination of services in a complex flow, using Lambda to program this orchestration is just a bad fit. One alternative is a more event-driven choreography, where the orchestration logic is not defined in one place, but emerges from the combination of all events and responses. If you prefer to avoid event-driven orchestration, and want to adopt a more explicit, declarative approach to orchestration, Step Functions give you a way to achieve this. Your state machine is defined in states language (JSON) and you pay for each transition, not for the execution time. Step Functions integrates with Lambda, Batch, DynamoDB, ECS, SNS, SQS, Glue and SageMaker.
Use API Gateway Service Proxies
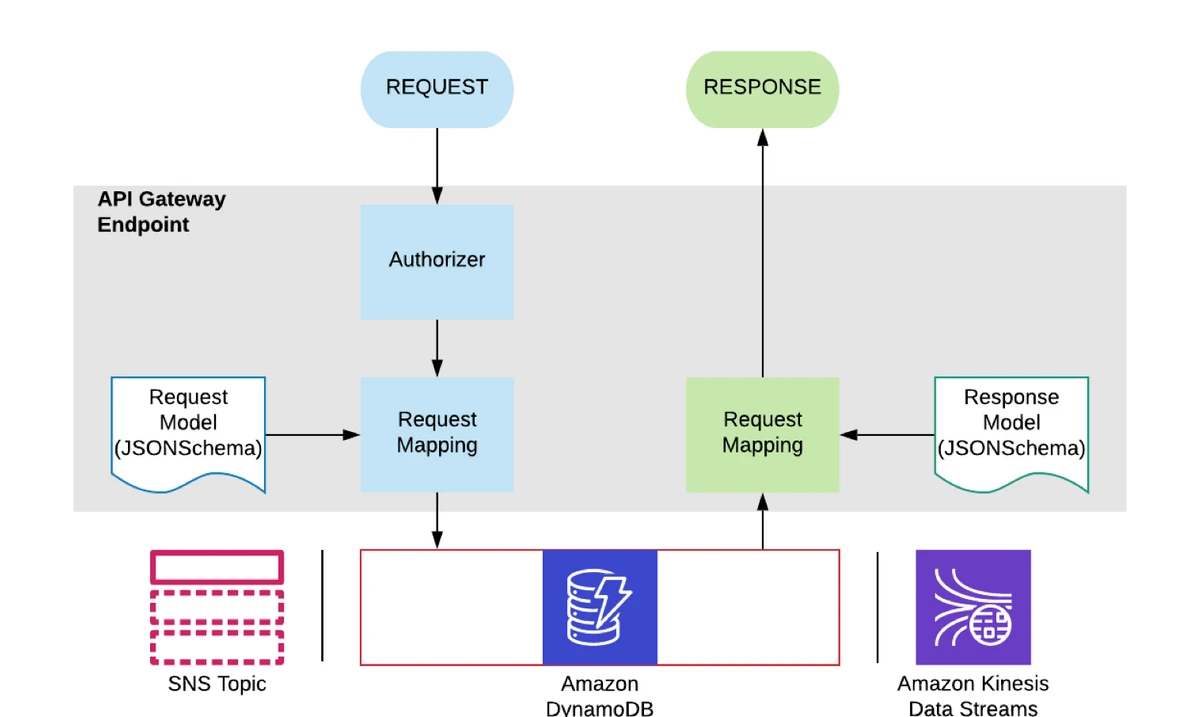
When you get started with Lambda, chances are you first started with an API Gateway triggering a Lambda function that interacted with DynamoDB. It’s less common to see examples of API Gateway talking directly to DynamoDB but it can be done. API Gateway can talk to any AWS service through a service proxy. In many cases, this can avoid the need for a Lambda altogether. You save the execution time and cost as a result. This will be covered in detail in an upcoming post so stay tuned!
Use Kinesis Analytics
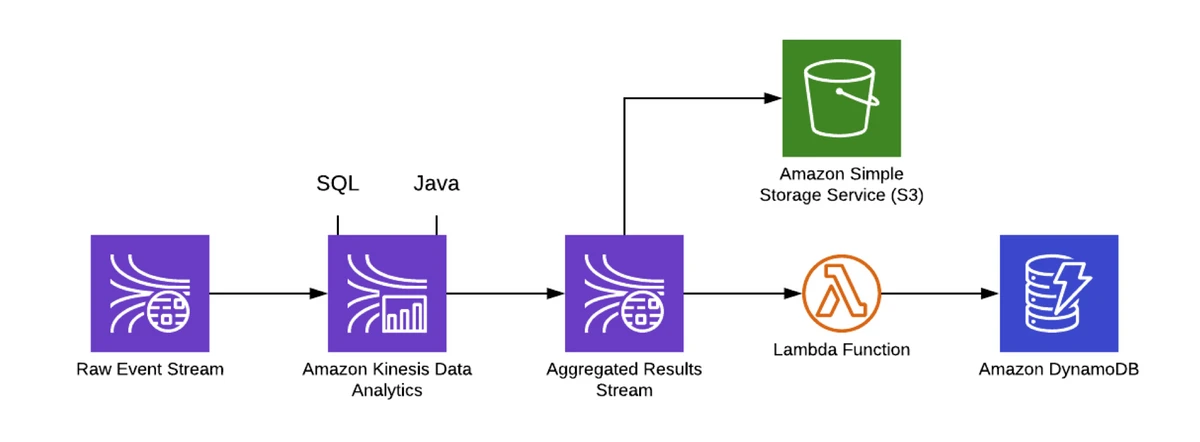
If your architecture features event streaming with Kinesis, these events can be used as a trigger for Lambda. You can also perform computation on the stream without Lambda by using Kinesis Analytics. This allows you to do aggregations using SQL or Java. It follows the principle of data locality, with the idea that it’s better to perform computation closer to the data rather than incur the disproportionate expense of moving data to a different location in order to operate on it.
Use SageMaker
If your computation is along the likes of data analytics or machine learning, SageMaker is an interesting option to consider. You can choose an in-built AWS container or devise your own. A SageMaker endpoint can then be created on-demand to create your instance and process your data. This gives good flexibility when you want to experiment with different compute sizes without over-provisioning.
Use Fargate
Fargate is marketed under AWS’ Serverless offerings since you don’t have to provision any instances to run containers. Fargate gives you the flexibility to run any Docker-based container images but avoids the ongoing maintenance burden of servers, clusters and scaling configuration. If Lambda is too limited for some cases, such as long-running workloads or legacy systems that are yet to be made truly serverless, Fargate might just fit the bill.
Use the Front End
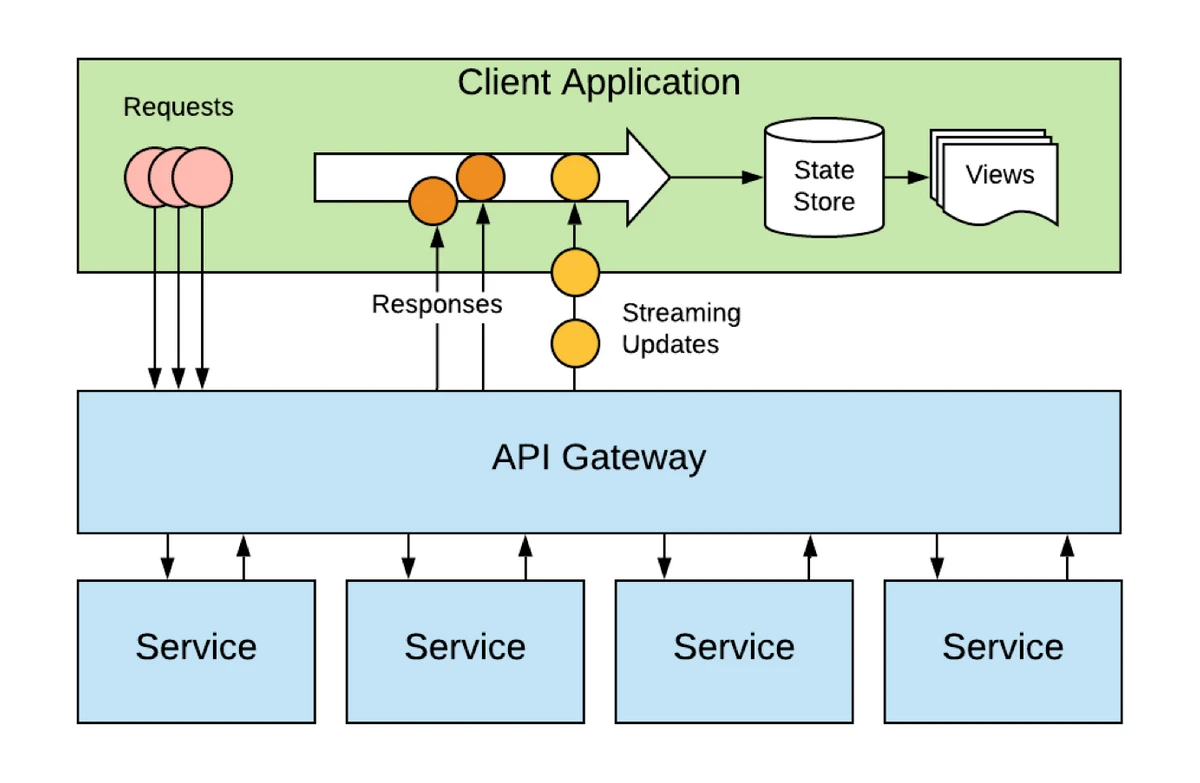
Rather than pushing all business logic into your back end in a proliferation of Lambdas, consider keeping APIs dumb and isolated. Then, allow client applications to combine data and orchestrate business processes in the front end. This allows different devices to have customised flows and behaviour. This may be more desirable than server-orchestrated flows that don’t quite work for every device type.
Use Direct Datastore Access
Over the course of history, much effort has been devoted to the deceptively simple job of reading and writing data from and to databases! It has been the purpose of many frameworks and ORMs and patterns across many technologies and languages. However, this job doesn’t have to involve any custom code. Within a Serverless project, there are a few options. As we’ve already mentioned, you can access AWS services like DynamoDB or S3 directly with API Gateway. You can also use AppSync to create GraphQL APIs directly from your DynamoDB or Aurora database. The Aurora Serverless option uses the Aurora Serverless Data API. When you use AppSync or the Data API with relational databases, you write SQL and leverage the compute power of the database to transform data where it is stored, optimizing for data locality. While we are on the topic of SQL, bear in mind that SQL can be used to selectively retrieve data from S3 (S3 SELECT), for ETL workloads in AWS Glue and for ad-hoc analytics with Athena.
Summary
I’ve written about many of the alternatives to performing computation in Lambda. The idea here is to move Serverless thinking away from being function-centric. Instead, accept the full gamut of managed compute services. Understand that the more functions you write, the more you must deploy, manage and coordinate. Think first in terms of events and only then consider what compute resource, if any, is required.
Eoin is CTO of fourTheorem and an author of AI as a Service, a Manning publication on building AI-enabled serverless applications on AWS. He is also the author of SLIC Starter, an open-source enterprise serverless starter kit, available on GitHub.
Get in touch to share your thoughts.